
Et si vous regardiez Git comme une base de donnée ? – Version Ruby
La première partie consacrée à Git vous a montré brièvement le stockage interne et surtout comment écrire une donnée, la lier à une clé et récupérer le contenu derrière cette clé. Pour cette deuxième partie, nous allons réaliser la même chose mais en utilisant un vrai langage de programmation, Ruby.

Contexte
Le but étant d’étudier git et de l’utiliser autrement qu’à l’habitude. Par contre, histoire de ne pas travailler dans le vent, il fallait bien développer un petit quelque chose. Nous sommes donc partis sur un grand classique des tutos web : la todo list !
La base était donc une simple application web, basée sur Sinatra, avec quelques petites actions basiques :
- lire l’ensemble des todos enregistrés
- ajouter un nouveau todo
- marquer un todo comme fait
- supprimer un todo
Le code de base provient d’un petit tuto sinatra disponible ici. Assez peu de différences à part le choix de la techno pour le rendu de l’html par l’utilisation de haml à la place de erb.
Je ne vais pas plus rentrer dans le sujet, l’application est vraiment simple et ce n’est pas l’objectif de cet article.
Et si on sortait un peu de notre coquillage ?
Tout ce qu’on a vu pour le moment c’est comment utiliser des couches basses de git depuis notre shell. C’est cool mais si le but était de ne pas trop se prendre la tête avec les fichiers c’est pas encore gagné.
Heureusement, on peut faire la même chose directement depuis du code source, sans utiliser git à la main et s’amuser à parser les commandes, leur retour, etc. Un peu plus fiable tout de même…
Pour ce faire, le point d’entrée est libgit2. Il s’agit d’une implémentation en c du cœur de git. C’est totalement portable, ça ne dépend de rien d’autre (donc ça ne dépend pas de git surtout). C’est utilisé en prod par pas mal de monde aussi.
Et surtout : il y a des bindings pour de très nombreux langages ! Et oui, on va pas coder en c, faut pas déconner quand même.
En particulier, il existe rugged, un binding de libgit2 en ruby. Et c’est celui que nous allons utiliser.
Voici donc la traduction de toutes ces commandes en ruby afin de les inclures dans notre superbe, notre magnifique, notre exceptionnelle application sinatra de TodoList !
Et voici la version raboteuse !
Pour l’installation, comme vous utilisez gem et bundler (what else?) c’est super simple. Ajoutez
gem 'rugged'dans votre Gemfile et installez le via bundle install.
Après un petit require 'rugged' vous pouvez enfin utiliser rugged.
Tout d’abord, il vous faut accéder à votre répository git.
Pour le créer :
repo = Rugged::Repository.init_at('my_repo.git', :bare)ou pour y accéder s’il existe déjà :
repo = Rugged::Repository.new('my_repo.git')Oui, on utilise un dépôt bare, pas besoin d’avoir une copie de travail.
La première vrai étape consiste donc à donner à git des données pour qu’il en crée un blob. Rien de plus simple :
blob_oid = repo.write '{"hello":"world!"}'Une solution sympa plutôt que de gérer le
hello world!en chaîne de caractères est, par exemple, de passer par yaml :require 'YAML' hello = {"hello": "world!"} blob_oid = repo.write hello.to_yamlL’avantage est que c’est dispo en standard en ruby, que la sortie est claire et lisible, qu’on peut facilement mapper des
structruby et que c’est un format qui semble plutôt aisé à fusionner si besoin.
La deuxième étape consiste à créer le tree correspondant. Pour ce faire nous allons avoir besoin d’un index qui va pouvoir faire le lien entre le blob et le chemin (la clé) que nous souhaitons.
index = Rugged::Index.new
index.add(:path => '1.json', :oid => blob_oid, :mode => 0100644)
tree_oid = index.write_tree(repo)Enfin, il faut créer un commit et mettre à jour la référence (master) avec ce tree. Pour ce faire nous avons besoin de quelques informations supplémentaires par rapport à la version shell. En fait c’est pas que ce soit nouvelles informations, juste que git est allé cherché comme un grand ce dont il avait besoin dans sa configuration.
options = {}
options[:tree] = tree_oid # l'arbre que nous souhaitons committer
options[:author] = {:email => '…@…', :name => 'sogilis', :time => Time.now}
options[:committer] = {:email => '…@…', :name => 'sogilis', :time => Time.now}
options[:message] = 'add 1'
# le parent de notre commit est vide si c'est le premier, sinon c'est head
options[:parents] = repo.empty? ? [] : [repo.head.target]
# on demande l'update de la ref ici, pas besoin d'une nouvelle commande
options[:update_ref] = 'HEAD'
Rugged::Commit.create(repo, options)Et voilà ! La même chose, en ruby !
Un dex
Bon, ce que vous ne voyez pas ici c’est que la gestion de l’index est par contre assez lourde. En effet, si vous désirez faire un deuxième commit qui rajoute une entrée sur un autre chemin… il vous faudra préalablement rajouter le premier à l’index. En clair il faut que l’index contienne tous les fichiers correspondant à la copie de travail courante. Si une entrée n’existe pas, elle sera alors simplement supprimée.
Voici une version naïve permettant de s’en affranchir, qui va créer un index en y ajoutant toutes les ressources voulues :
index = Rugged::Index.new
unless repo.empty?
tree = repo.lookup(repo.head.target).tree
tree.walk_blobs(:postorder) do |root, entry|
index.add(:path => "#{root}#{entry[:name]}",
:oid => entry[:oid], :mode => 0100644)
end
endEn gros ce qui se passe :
- récupération d’un nouvel index
- si le dépôt est vide, on ne fait rien, évidemment
- on récupère le hash du commit pointé par head (
repo.head.target) - et on accède à l’arbre (
repo.lookup(hash).tree) - on parcourt alors l’arbre à la recherche des
blobset on les ajoute à l’index
walk_blobs permet de trouver uniquement les blobs, il est possible de parcourir un arbre pour passer uniquement sur les autres arbres ou alors de tout parcourir sans distinction.
Maintenant que vous avez compris le principe, on peut tout de même faire ça plus simplement :
index = Rugged::Index.new
unless repo.empty?
tree = repo.lookup(repo.head.target).tree
index.read_tree(tree)
endread_tree s’occupe justement pour nous de lire tous les blobs correspondant à un arbre et les ajoute à l’index.
Et si on lisait ?
Petit aparté sur l’index terminé (enfin presque…), il est maintenant intéressant de lire une donnée basée sur sa clé.
Nous allons donc parcourir l’arbre relié à head à la recherche de la clé.
Une première version est d’utiliser ce qu’on vient de faire avec l’index :
def show repo, key
return nil if repo.empty?
tree = repo.lookup(repo.head.target).tree
tree.walk_blobs(:postorder) do |root, entry|
if "#{root}#{entry[:name]}" == key
oid = entry[:oid]
return repo.read(oid).data
end
end
nil
endAinsi show(repo, '1.json') retournera '{"hello":"world!"}' (si vous l’avez stocké en json). Et si vous avez fait du YAML, vous pourrez accéder à l’objet en faisant un YAML.load(show(repo, '1.json')).
Une autre solution est d’accéder directement à l’objet sous le tree :
def show repo, key
return nil if repo.empty?
tree = repo.lookup(repo.head.target).tree
oid = tree[key][:oid]
repo.read(oid).data
endUn peu plus simple, non ? Sauf que ce n’est pas suffisant. Cela marche très bien dans ce cas, mais la réalité est un poil plus complexe. Ceci ne fonctionne que si vous êtes dans le cas d’une clé posée à la racine. Si vous utilisez des clés “hiérarchiques” (comme des fichiers placés dans un répertoire) alors vous aurez une structure légèrement différente.
Souvenez-vous de la structure présentée dans le premier article :
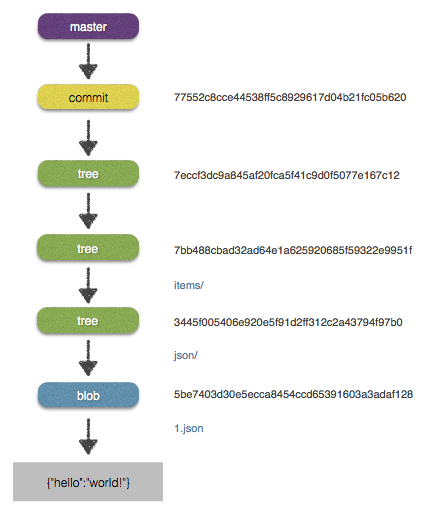
L’arbre pointé par le commit va vous permettre d’accéder au répertoire. Il faudra ensuite recommencer le travail sur l’arbre correspondant au répertoire pour trouver le fichier.
En plus clair, si votre clé est items/1.json cela ressemblera à :
tree = repo.lookup(repo.head.target).tree
items_oid = tree["items"][:oid]
items_tree = repo.lookup(items_oid)
oid = items_tree["1.json"][:oid]
repo.read(oid).dataEt évidemment il faudra faire ça de manière récursive si nécessaire.
Voici donc une solution permettant d’accéder à vos données de manière un peu plus sympa :
def show repo, key
return nil if repo.empty?
tree = repo.lookup(repo.head.target).tree
paths = path.split('/')
oid = get_oid repo, tree, paths
repo.read(oid).data
end
def get_oid repo, tree, paths
key = paths.shift
return nil if tree[key].nil?
oid = tree[key][:oid]
return oid if paths.empty?
return nil if tree[key][:type] != :tree
get_oid repo, repo.lookup(oid), paths
endEvidemment votre show(repo, '1.json') fonctionnera toujours pareil.
Cette méthode est un peu plus explicite que celle utilisant walk_tree mais surtout elle permet de ne pas parcourir potentiellement toutes les branches afin de trouver le contenu de la bonne clé.
Il existe encore une autre solution pour récupérer les données liées à chemin : l’index.
Une fois l’index relu via index.read_tree(tree) vous pouvez accéder à n’importe quel fichier facilement :
def show repo, path
return nil if repo.empty?
tree = repo.lookup(repo.head.target).tree
index = Rugged::Index.new
index.read_tree(tree)
oid = index[path][:oid]
repo.read(oid).data
endA vous de choisir celle qui vous semble la plus intéressante 🙂
Résultat
On a donc vu comment écrire et lire des données dans git sous forme de couple clé/valeur.
Vous conviendrez que la lecture (surtout) est pas génialissime, un peu lourde. Il manque une petite couche d’abstraction au dessus de rugged pour accéder aux items facilement.
Néanmoins cela fonctionne !
Extra
Si on veut aller plus loin, on peut commencer par naviguer dans l’historique.
Par exemple, au lieu d’utiliser repo.head.target comme révision de base, il suffit de prendre la révision d’un parent de ce commit et ensuite de cherche le/les objets souhaités.
Par exemple, si on souhaite trouver le contenu de 1.json à l’avant dernière révision, on peut le réaliser de la sorte :
# arbre du commit de head
tree = repo.lookup(repo.head.target).tree
# récupération de la révision parente
hash = tree.parents.first
# tree du commit
prev = repo.lookup(hash)
# on récupère alors l'oid
oid = prev['1.json'][:oid]On vient alors de naviguer dans l’historique afin de récupérer les données telles qu’elles étaient présentes dans le passé.
Gungnir
Vous pouvez trouver le code de l’application de TodoList avec stockage dans git sur notre github, dans le projet gungnir.
Pour le tester, rien de plus simple :
bundle install
bundle exec rackupet rendez-vous sur http://localhost:9292. Vous pouvez alors ajouter des items, les marquer comme fait et les supprimer. Et aussi naviguer dans les différentes versions existantes !
Et pour une petite démo en live rendez-vous sur gungnir.herokuapp.com/
Conclusion
Ainsi s’achève notre petite découverte de git comme moteur de stockage.

Il y a encore beaucoup de choses à découvrir comme par exemple les possibilités d’utilisation concurrente, les branches, les hooks, etc. Bien que l’accès ne soit pas des plus simples, pouvoir profiter du moteur de git peut être vraiment intéressant.
Ha oui, un dernier rappel sur git avant de se quitter. Sogilis dispense toujours des formations Git !
Ressources
- Git: the NoSQL database par Brandon Keepers
- Git Internals : Chapitre 9 de Pro Git
- rugged