
Classification des systèmes de stockage NoSQL
Dans un billet précédent, nous avons établi une brève description des systèmes de stockage NoSQL (“Not Only SQL”) en partant des cas d’utilisation qu’ils visent à résoudre. Après avoir dégagé des points de comparaison entre ces technologies et les bases de données relationnelles, plus traditionnelles, nous en avons conclu que les moteurs de stockage NoSQL ne sont pas destinés aux mêmes usages que les bases relationnelles classiques. Par conséquent, ces deux technologies peuvent très bien cohabiter au sein d’un même logiciel sans interférer entre elles ; l’idée étant de toujours utiliser un outil adapté au problème qu’on souhaite résoudre.
La famille des systèmes NoSQL compte des systèmes très hétérogènes qui répondent chacun à des besoins très spécifiques. De façon générale, on arrive à les classer en quatre grands ensembles : les bases clé-valeur, les bases documents, les bases orientées colonnes et les bases de type graphe.
Les bases de données clé-valeur
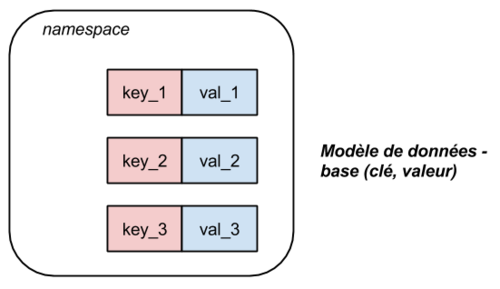
Une base de données clé-valeur est assimilée à une collection (un dictionnaire) de paires (clé, valeur) où la clé et la valeur sont des chaînes de caractères quelconques. Le système de stockage ne connait pas la structure de l’information qu’il manipule (s’agit-il d’une date ? d’un numéro de téléphone ? d’un article de blog ?) et l’information ne peut être retrouvée que par l’intermédiaire de la clé qui lui est associée.
Puisque les requêtes se font uniquement sur les clés, les bases clé-valeur sont très peu expressives en termes de langage d’interrogation de la base. De plus, le système n’ayant pas d’indice sur la structure de l’information qu’il stocke, tous les traitements (extraction du contenu, application de filtres…) doivent être effectués en dehors du système par l’utilisateur. En particulier, il est très difficile pour de tels systèmes de ne mettre à jour (ou de ne lire) qu’une seule partie de la valeur associée à une clé. Il est en effet plus aisé de lire et de réécrire complètement la donnée.
De par leur simplicité de fonctionnement, les bases de données clé-valeur sont très facilement scalables : des systèmes comme Redis ou Riak sont capables de gérer des millions - voire des milliards - d’entrées et garantissent des temps de réponse en lecture et en écriture très bas. Ils sont majoritairement utilisés pour cacher du contenu en temps réel et ainsi décharger des bases de données plus structurées mais aussi plus lente à traiter l’information.
Exemples : Riak, Redis, Amazon DynamoDB, MemCached…
Les bases de données documents
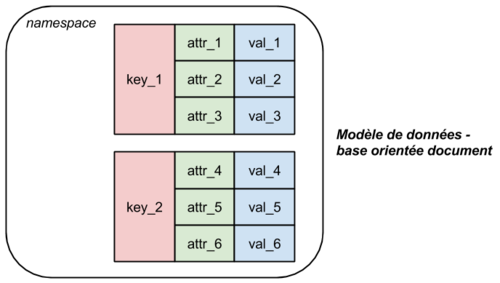
Les bases de données orientées document consistent en une collection de paires (clé, document) où le document lui-même une collection de paires (clé, valeur). En ce sens, on peut voir dans ces bases de données une version raffinée et généralisée des bases clé-valeur. Le document est l’unité d’information stockée, et la scalabilité de tels systèmes est en général très bonne. Le partitionnement de l’information se fait sur la clé principale, tout comme dans le cas des bases de données clé-valeur.
L’unité d’information stockée est ici le document qui encode et encapsule la donnée dans un format semi-structuré (comme le XML ou le JSON). L’information dispose de ce fait d’une structure interne, ce qui permet un langage de requête bien plus expressif que pour les ensembles clé-valeur. En effet, le système est capable de filtrer un document selon les attributs demandés, et même de les classer entre eux (par ordre alphabétique, par exemple). L’adoption d’un format semi-structuré pour modéliser l’information laisse une grande flexibilité quant à la structure du document, facilitant ainsi son évolutivité au cours du temps.
Exemples : MongoDB, RethinkDB, CouchDB, Terrastore…
Les bases de données orientées colonnes
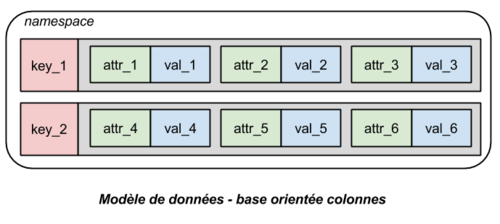
Dans les bases orientées colonnes, les tables dans lesquelles les données sont stockées traditionnellement en SQL sont partitionnées verticalement (suivant les colonnes). L’information est représentée sous forme de colonnes indexées par une même clé. Au sein de ce type de système, une même donnée peut être fragmentée sur plusieurs machines distinctes.
Ces systèmes favorisent les opérations sur des attributs isolés de l’information stockée. En effet, avec un tel partitionnement de l’information il n’est plus nécessaire de retrouver l’intégralité d’une ligne si on ne souhaite récupérer qu’un seul attribut de celle-ci. De plus, puisque chaque colonne est stockée sur une machine particulière, les systèmes orientés colonnes sont très efficaces lorsqu’il s’agit d’effectuer des opérations d’agrégation sur des attributs précis (comme un calcul de somme, de valeur maximale ou moyenne…). En revanche, puisque les données sont partitionnées sur plusieurs machines, ces systèmes sont peu recommandés lorsqu’il est nécessaire de modifier régulièrement les lignes intégralement. En effet les lignes doivent alors être rechargées depuis des machines/disques distincts.
De par leur structure, ces systèmes supportent bien le partitionnement sur plusieurs machines. Puisque l’unité de stockage est la colonne, l’information est plus facilement accessible - dans certains cas d’utilisation - puisqu’il n’est pas nécessaire de verrouiller l’accès à toute la ligne le temps de la lecture/écriture. Les moteurs de stockage orientés colonnes peuvent être utilisés pour implémenter des systèmes de fichiers distribués fiables, assurant une redondance des données automatique.
Exemples : Apache HBase, Apache Cassandra, Hypertable, Apache Accumulo…
Les bases de données de type graphe
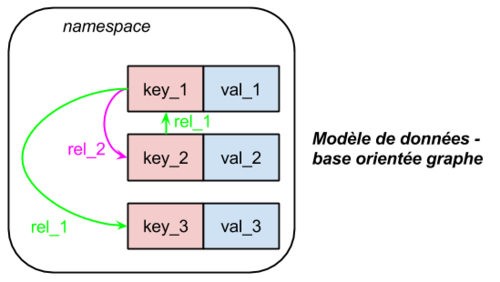
Une base de données orientée graphe est une base de données orientée objet utilisant la théorie des graphes, donc avec des nœuds et des arcs, permettant de représenter et stocker les données. Par définition, une base de données orientée graphe correspond à un système de stockage qui respecte des relations d’adjacence entre éléments dits “voisins” : chaque voisin d’une entité est accessible grâce à un pointeur physique. Ces systèmes tirent parti des algorithmes standards issus de la théorie des graphes pour manipuler les données. Il n’y a pas besoin de calculer un index sur les données, puisque la base peut être entièrement parcourue efficacement (plus court chemin - Dijkstra, parcours en profondeur, en largeur…). Ces algorithmes sont optimisés, revus et corrigés depuis de nombreuses années. Ces bases de données sont ainsi plutôt adaptées lorsqu’il s’agit de traiter des informations présentant un haut degré de corrélation.
Un tel type de structure se révèle ainsi pertinent dans le cas de données complexes. En effet, les bases graphes sont idéales pour des recherches du type “partir d’un nœud et parcourir le graphe” plutôt que “trouver toutes les entités du type X”, plus adaptées aux bases de données relationnelles traditionnelles. Il est cependant possible dans cette catégorie de bases d’effectuer des recherches de ce dernier type, en couplant le système de stockage à un système d’indexation tel que Apache Lucene (ou ses dérivés Apache SolR/ElasticSearch).
Les moteurs de stockage de type graphes sont particulièrement appropriés lorsqu’il s’agit d’exploiter les relations entre les données (eg des connaissances entre des personnes au sein d’un réseau social). Les bases de données orientées graphes sont essentiellement utilisées dans la modélisation des réseaux sociaux, dans lesquels il est possible de déterminer rapidement les profils associés à un profil donné, ou le degré de séparation entre des profils distincts.
Par construction, ces bases de données n’offrent pas une bonne scalabilité horizontale (ie par accroissement du nombre de serveurs) car les mécanismes de synchronisation des écritures sur des graphes nécessite des opérations complexes. Ces systèmes sont donc fragiles au partitionnement des données sur des supports physiques distincts. Dans ce cas, la mise à l’échelle peut être compensée par une augmentation de la puissance de calcul/stockage/mémoire vive du serveur.
Exemples : Neo4J, Infinite Graph, DEX…
Cohérence, disponibilité et partitionnement
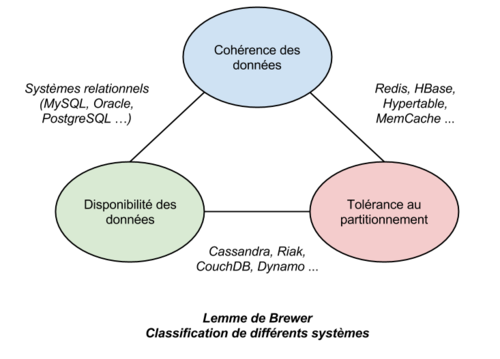
A la suite de cette description, on comprend que le mouvement des bases de données NoSQL contient plusieurs approches qui ont une architecture qui leur est propre et qui traitent des cas d’utilisation bien définis. Il convient donc de choisir l’outil qui répond le mieux au problème posé, à la fois en termes de modélisation mais aussi de répartition des données. En parallèle de cette classification, il existe trois caractéristiques très importantes à prendre en compte lors du choix d’un moteur de stockage : la cohérence des données, la disponibilité des données et le partitionnement physique des données.
Un système est dit cohérent lorsque chacun de ses clients dispose de la même vue d’ensemble des données qu’il détient à un instant précis. Lorsqu’une modification sur les données a lieu, les changements sont soit visibles par tous, soit invisibles de tous.
La disponibilité des données signifie que chaque client doit pouvoir lire et écrire dans la base sans subir de “temps morts” dus à des erreurs de réseau et/ou de machines.
Enfin, un système de stockage distribué est dit tolérant au partitionnement physique lorsqu’il supporte la distribution de la charge de stockage sur des machines physiques distinctes, interconnectées par un réseau. Un tel système est entre autres capable de contourner une panne d’un de ses nœuds en redirigeant automatiquement les requêtes sur d’autres nœuds disponibles.
Un résultat connu sous le nom de lemme de Brewer (en) prouve que seulement deux de ces caractéristiques sur trois peuvent être présentes simultanément au sein d’un système de gestion de bases de données (qu’il soit NoSQL ou non). Les systèmes relationnels, par exemple, supportent très bien la disponibilité et la cohérence des données mais sont relativement pas (ou peu) adaptés au partitionnement physique - bien que certains travaux aillent dans ce sens, notamment sur PostgreSQL. Les systèmes NoSQL, quant à eux, sont conçus pour être distribués sur un réseau de machines physiques, ce qui implique un compromis entre la cohérence des données et la disponibilité des serveurs. Souvent, ces systèmes implémentent une notion de cohérence finale (ie les modifications sur les données sont propagées sur toutes les machines au bout d’un certain temps) afin de garantir une haute disponibilité des données.
Références
- Un catalogue à jour des systèmes de stockage NoSQL existants. nosql-database.org
- Une vue approfondie de plusieurs catégories de systèmes NoSQL. Not Only SQL (en)