
Un découpage naturel du code
Quotidiennement, un développeur est amené à réfléchir à 2 types d’exigences en écrivant du code :
- le fond ou exigences fonctionnelles : comment le faire fonctionner (i.e. que la machine fasse ce qui est attendu).
- la forme ou exigences techniques : comment rendre ce code lisible, maintenable, évolutif, etc.
La forme tient une part plus ou moins importante en fonction du contexte du projet. Entre un POC et une application aéronautique, les exigences ne seront bien évidement pas les mêmes. Cependant, un minimum de lisibilité est bien souvent nécessaire, quand bien même le code serait jeté à terme, ne serait-ce que pour pouvoir se relire.
Nous allons voir dans cet article une stratégie permettant d’atteindre une sorte de minimum hygiénique du code lisible.
Le principe
Le principe est basé sur le découpage du code pour qu’il puisse être représenté sous forme d’un graphe (unidirectionnel hiérarchique) comme celui-ci :
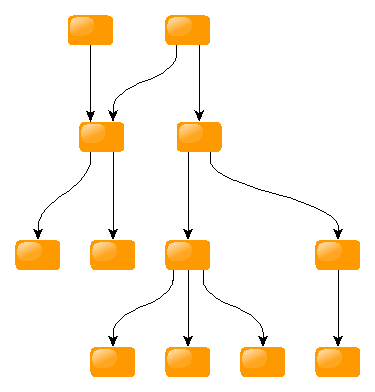
Chaque nœud représente une fonction, et chaque lien un appel de fonction. Ainsi, A -> B signifie que la fonction A appelle la fonction B.
De plus, dans ce graphe, les fonctions doivent être regroupées par niveaux d’abstraction, ce qui pourrait donner avec le graphe ci-dessus :
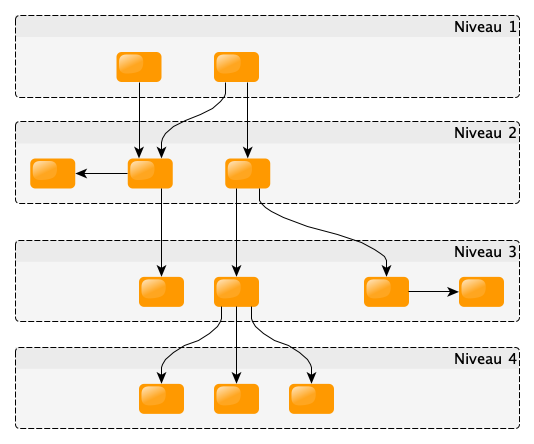
Plus le niveau est élevé, plus le code devient abstrait : on ne va plus manipuler des nombres et des chaînes de caractères, mais des structures ou objets représentant des notions plus proches de la réalité (ex : un client, une commande…).
La règle à suivre est la suivante :
Une fonction de N ne peut appeler que des fonctions de niveau inférieur ou égal à N.
Voici la théorie. Nous allons voir maintenant comment appliquer ce principe sur un exemple.
Exemple concret
Prenons l’exemple d’un site d’informations constitué d’articles. Chaque article est associé à un ou plusieurs tags et une ou plusieurs catégories.
Nous devons développer une fonction qui retourne quelques articles connexes à l’article courant suivant les règles suivantes :
- cette liste doit contenir 5 articles, ou être vide s’il n’est pas possible de trouver 5 articles.
- les articles sont connexes s’ils partagent un tag commun.
- la liste retournée ne doit pas être déterministe (les articles sélectionnés doivent être aléatoires).
Nous avons à disposition l’article courant, et tous les articles sont stockés dans une base de données.
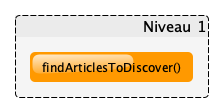
Premier niveau d’abstraction
Pour commencer, nous devons créer une fonction comme point d’entrée de notre algorithme :
func findArticlesToDiscover(current Article) []Article {
...
}
Niveau 2
Ensuite, nous devons nous demander quelles fonctions plus concrètes notre première fonction a besoin :
func findArticlesToDiscover(current Article) []Article {
relatedArticles := findAllRelated(current)
articlesToDiscover := takeManyRandomly(relatedArticles, 5)
if len(articlesToDiscover) < 5 {
return []Article{}
}
return articlesToDiscover
}
Alors apparaît le deuxième niveau d’abstraction :
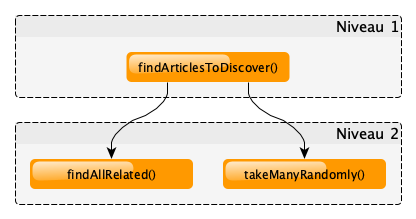
Niveau 3
Nous répétons la même démarche avec la fonction findAllRelated()…
func findAllRelated(current Article) []Article {
var relatedArticles []Article
for _, article := range findAll() {
if ArticlesEqual(current,article) {
continue
}
if overlaps(current.Tags, article.Tags) {
relatedArticles = append(relatedArticles, article)
}
}
return relatedArticles
}
… puis la fonction takeManyRandomly()…
func takeManyRandomly(all []Article, count int) []Article {
if len(all) < count {
return all
}
var articles []Article
var article Article
remains := make([]Article, len(all))
copy(remains, all)
for len(articles) < count {
article, remains = removeOneRandomly(remains)
articles = append(articles, article)
}
return articles
}
… ce qui donne :
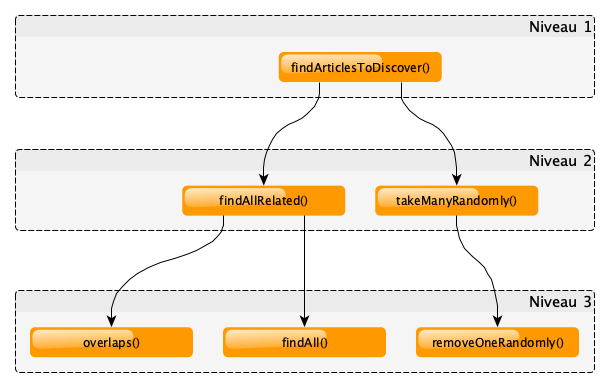
Remaniement
Nous venons de créer plusieurs fonctions qui se retrouvent un peu mécaniquement regroupées par niveaux d’abstraction. Mais cette organisation est-elle pertinente ?
Comparons par exemple les fonctions overlaps() et removeOneRandomly() :
overlaps()est une fonction qui manipule des tableaux destringpour retourner un booléen.removeOneRandomly()en revanche, manipule un tableau d’Article.
Or, un Article est composé de types de base du langage (string, int…). Ces 2 fonctions ne travaillent donc pas avec le même niveau d’abstraction : elles ne devraient pas être regroupées.
En faisant de même avec findAll(), le schéma suivant émerge :
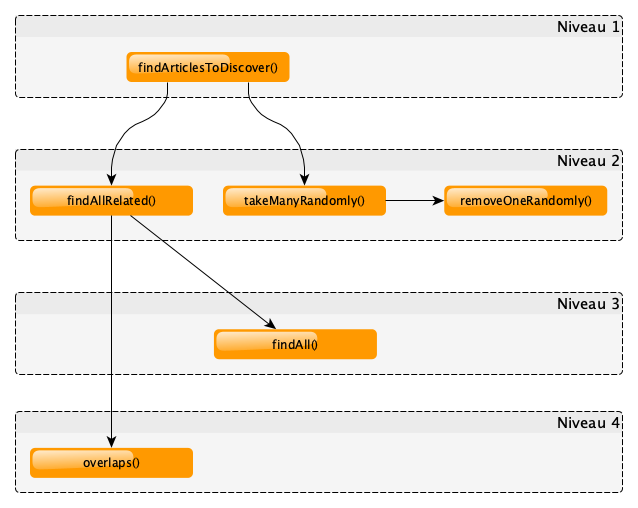
Ainsi, nous pouvons définir le périmètre de chaque niveau, ce qui permettra de faciliter l’organisation de futures fonctions :
- Niveau 1 : les fonctions métier répondant aux exigences fonctionnelles.
- Niveau 2 : les fonctions manipulant des concepts métier, sortes de briques élémentaires métier.
- Niveau 3 : l’abstraction de la base de données (ou autre infrastructure).
- Niveau 4 : les fonctions manipulant les types de base du langage.
Que gagne-t-on à suivre ce découpage ?
En dehors des bienfaits potentiels à tout découpage (faciliter les tests, réduire la complexité de chaque fonction…), d’autres éléments peuvent être intéressants :
Le code est plus facile à comprendre puisque l’on suit le raisonnement naturel, partant d’une vision globale (le niveau d’abstraction le plus élevé) pour aller progressivement dans le détail.
De la même manière, la séparation par niveaux d’abstraction évite de mélanger détails et concepts globaux. Imaginez une fonction qui regrouperait le code de findAllRelated() et takeManyRandomly() : illisible. Par analogie, dans un jeu de société, c’est un peu comme si, lors de l’explication des règles de victoire, on parlait en même temps d’un point de détail sur un mécanisme bien précis : c’est du bruit.
Pour conclure
Nous avons vu un principe relativement simple permettant de produire un code avec un niveau minimum de lisibilité.
Le principe exposé ici est une stratégie “top-down” où l’on part de ce dont on a besoin pour “descendre” vers “comment” le construire. L’approche inverse consisterait à partir des données disponibles pour construire petit à petit ce que l’on doit retourner.
Les quelques idées exposées dans cet article rejoignent le principe Single Level of Abstraction de Clean Code à quelques détails près :
- nous parlons ici de programmation procédurale.
- nous ajoutons des contraintes supplémentaires entre les niveaux d’abstractions.
- le découpage et aussi guidé dans cet article par une approche “top-down”.
Bien que ce principe ne parle que de découpage de fonctions, il peut malgré tout être intéressant de l’appliquer avec de la programmation orientée objet, quitte à ce que ce soit localement dans une classe. En effet, qui n’a jamais croisé une méthode qui aurait profité d’être scindée en morceaux plus petits ?