
Stratégies de tests logiciels : Pyramide des tests, mocks et alternatives
La pyramide des tests
Lorsqu’on parle de stratégie de test, on évoque souvent la pyramide des tests. On peut lire plusieurs versions de cette pyramide, mais l’une des plus courantes ressemble à cette image [source: openclassrooms] :
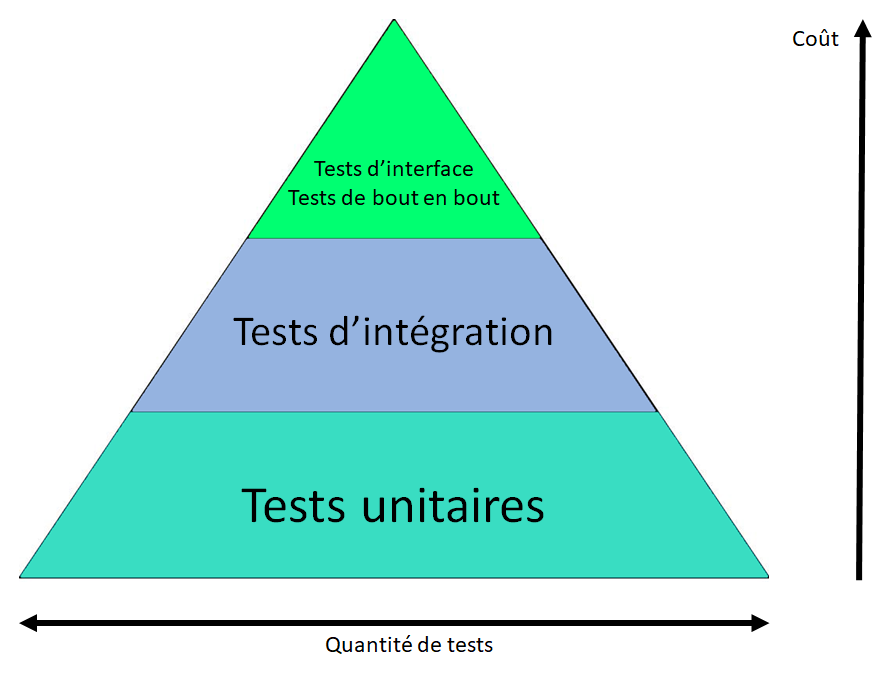
À la base de la pyramide, on a les fameux tests unitaires. Ce sont des tests automatiques, rapides à exécuter, faciles à écrire et qui testent un périmètre très restreint du système. Ensuite, au-dessus des tests unitaires, il y a les tests d’intégration qui permettent de tester un périmètre plus grand, avec plus de “composants”, qui sont donc plus longs et plus difficiles à exécuter. Et enfin, on a les tests de haut niveau, qui testent un périmètre beaucoup plus large, parfois l’application de bout en bout (end-to-end), en incluant potentiellement l’interface graphique. Ce sont des tests beaucoup plus longs que les tests unitaires à cause de la quantité de code testé et de l’implication éventuelle de l’infrastructure et de l’interface graphique. Ils sont difficiles à automatiser et sont même parfois exécutés manuellement. On parle aussi de tests d’acceptation permettant de s’assurer que l’application répond bien au besoin fonctionnel, lesquels sont parfois exécutés par des équipes QA dédiées.
La stratégie de la pyramide des tests nous dit qu’il faut privilégier le nombre de tests unitaires par rapport aux autres types de test. Les tests unitaires sont notre “première ligne de défense”, à exécuter très régulièrement, ce qui nous permet d’avoir une boucle de feedback assez courte sur d’éventuelles régressions. Les tests à un niveau plus élevé sont également importants, mais ils représentent une seconde “ligne de défense”, en nombre plus petit et avec une boucle de feedback plus longue.
Cependant, cette vision a l’inconvénient d’être très imprécise sur la séparation entre un test unitaire et un test d’intégration. À quel moment un test cesse-t-il d’être unitaire ? Ceci engendre parfois beaucoup de confusion lors de débats car on peut avoir différentes définitions de ce qu’est un test unitaire.
Les différentes approches sur les tests unitaires
Classiquement, on définit un test unitaire selon trois attributs :
- Un test unitaire se concentre sur une seule unité.
- Le temps d’exécution doit être suffisamment faible.
- L’unité testé doit être isolé.
En réalité, cette définition des tests unitaires n’est pas universellement acceptée. Le désaccord porte généralement sur ce que signifie exactement l’isolement : est-ce le code qui doit être testé de manière isolée ou les tests unitaires qui doivent être effectués isolément les uns des autres ?
L’unité du test peut aussi être soumise à interprétation : à quel point une unité de code devrait-elle être petite ? Selon les contextes et les langages de programmation, plusieurs éléments du code peuvent constituer une unité. Il peut s’agir d’une fonction, d’une classe, d’un module. Cela peut également dépendre de la façon dont on définit l’isolement. Si l’on adopte la position d’isoler chaque classe individuelle les unes des autres, alors il est naturel d’accepter que l’unité de code testée doit également être une seule classe, ou une méthode à l’intérieur de cette classe.
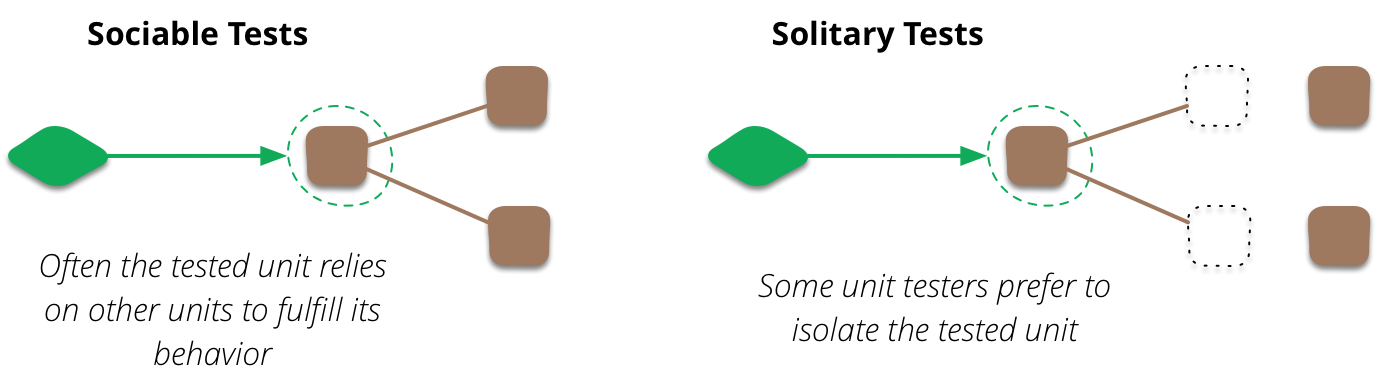
Martin Fowler résume le débat en citant deux approches possibles pour l’écriture des tests [UnitTest]. Il y a l’approche par tests sociables (aussi nommée approche classique), qui s’applique lorsque le code testé dépend d’autres parties du code, permettant au test de couvrir plusieurs classes à la fois. Il y a aussi l’approche par tests solitaires (parfois appelée approche mockiste), qui concerne les tests qui isolent une unité des autres parties du code. Dans ce cas, une unité testée est souvent une seule classe qui a été isolée en utilisant des techniques de stubs, mocks, fakes, dummy ou spies. Meszaros utilise le terme de Test Double pour désigner tout type d’objet factice utilisé à la place d’un objet réel pour les tests.
L’inconvénient des tests trop unitaires
Si on suit l’approche par tests solitaires et que l’on souhaite implémenter la pyramide de tests, on arrive à une base de code où chaque classe est testée unitairement et indépendamment des autres en simulant leurs interactions avec des objets factices (c’est-à-dire, des test doubles).
Pour illustrer cette situation, prenons une base de code dont l’architecture est la suivante :
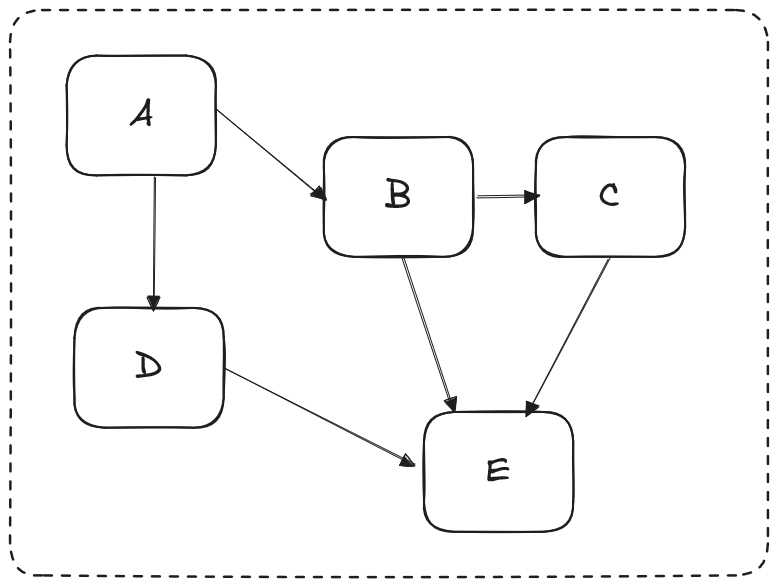
Chaque boîte est une classe et chaque flèche est une dépendance simple envers une autre classe.
Une stratégie de test où chaque classe est testée unitairement en isolation des autres classes ressemblerait alors à cela :
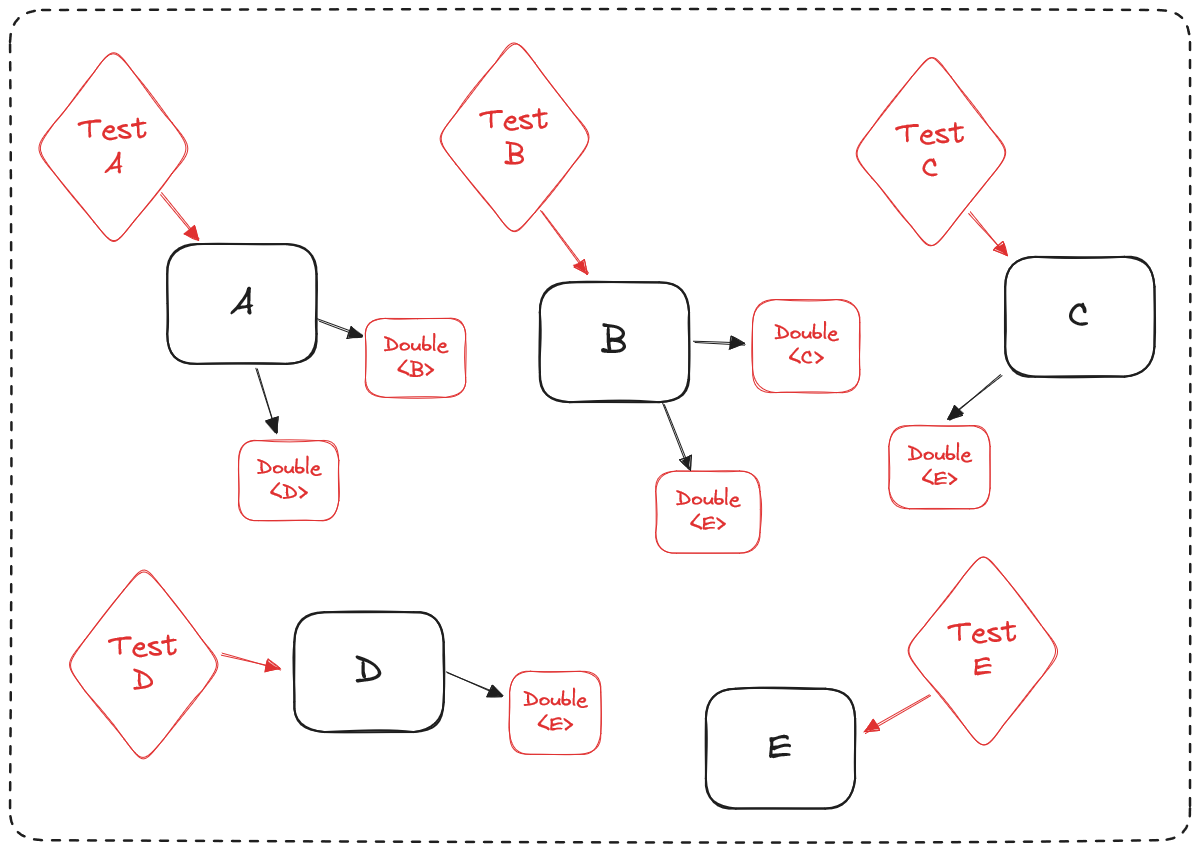
Chaque test instancie un double (mock, stub, etc.) pour chaque classe dont il a besoin pour tester la classe en question, et il va injecter ces objets factices dans l’objet testé.
Cette situation a un énorme avantage : l’ensemble des classes sont ainsi testées séparément. Si un bug apparaît dans une classe, seul le test associé à cette classe échouera. On est donc sûr que chacune des “briques” élémentaires de notre architecture implémente bien le comportement qu’on attend, ce qui augmente la résilience du système entier aux erreurs de programmation. On peut comprendre le fonctionnement de la classe juste en étudiant ses tests, comme une documentation à l’intention du futur développeur ou développeuse qui doit intervenir sur cette classe.
Le problème principal survient lorsque l’on veut modifier l’architecture de la base de code. Si l’on veut renommer des éléments, diviser une classe en deux, extraire un nouveau concept dans un nouvel objet, déplacer des responsabilités, etc., les tests vont rapidement échouer à cause des doubles. On est dans une situation où les tests sont fragiles et sont coûteux à maintenir lors de nos tâches de refactoring. Chaque modification nécessitera que les test soient modifiés, en changeant le comportement des doubles ou en en ajoutant d’autres.
Cet effort supplémentaire rend le refactoring beaucoup plus coûteux, ce qui a tendance à décourager toute tentative d’amélioration de l’architecture. L’architecture d’une solution devient alors figée dans le temps. Ainsi, les erreurs sur les choix d’architecture persisteront et la dette technique augmentera.
L’autre problème d’une surutilisation des doubles dans les tests est une diminution significative de leur lisibilité. Chaque test nécessite une longue étape de setups de mocks, stubs, etc., qui dépendent fortement de la façon dont le code de production a été écrit. Il devient alors difficile de comprendre l’intention du test sans avoir à lire le code testé, ce qui complique leur maintenance dans le temps.
L’erreur ici vient du fait que les tests vérifient l’implémentation d’une solution plutôt que le comportement du logiciel. Les tests sont ainsi trop liés aux détails d’implémentation et tout changement de cette implémentation aura pour effet néfaste de faire échouer tous les tests qui en dépendent.
Une stratégie de test alternative
Une des alternatives à cette stratégie de test est de changer la façon dont on implémente les tests, notamment en suivant la démarche suivante :
Tester le comportement du software, plutôt que ses détails d’implémentation
Pour le dire autrement, le test doit vérifier un besoin, une fonctionnalité ou une user story de haut niveau, c’est-à-dire quelque chose que l’utilisateur du logiciel peut décrire. Ce comportement peut être implémenté de différentes façons, avec différents choix d’architectures, de solutions techniques, de bibliothèques tierces, etc. Mais le test ne doit PAS dépendre des solutions qui ont été choisies. Si une personne change radicalement l’implémentation sans toucher au comportement de base, les tests doivent continuer à passer.
En pratique, cela suppose que les tests doivent être implémentés au niveau des APIs public, c’est-à-dire au niveau des contrats exposés publiquement pour déclencher le comportement d’une partie du software. Ces APIs peuvent prendre la forme d’une interface publique, un port dans une architecture hexagonale, les commandes dans un contrôleur, etc. Elles sont les points d’entrée d’un module (c’est-à-dire un package, un dossier ou un namespace). Le reste des classes représente alors les détails d’implémentation qui sont encapsulés dans le module.
Dans l’exemple précédent, cette stratégie de test consiste à implémenter des tests au niveau des API définies par la classe A :
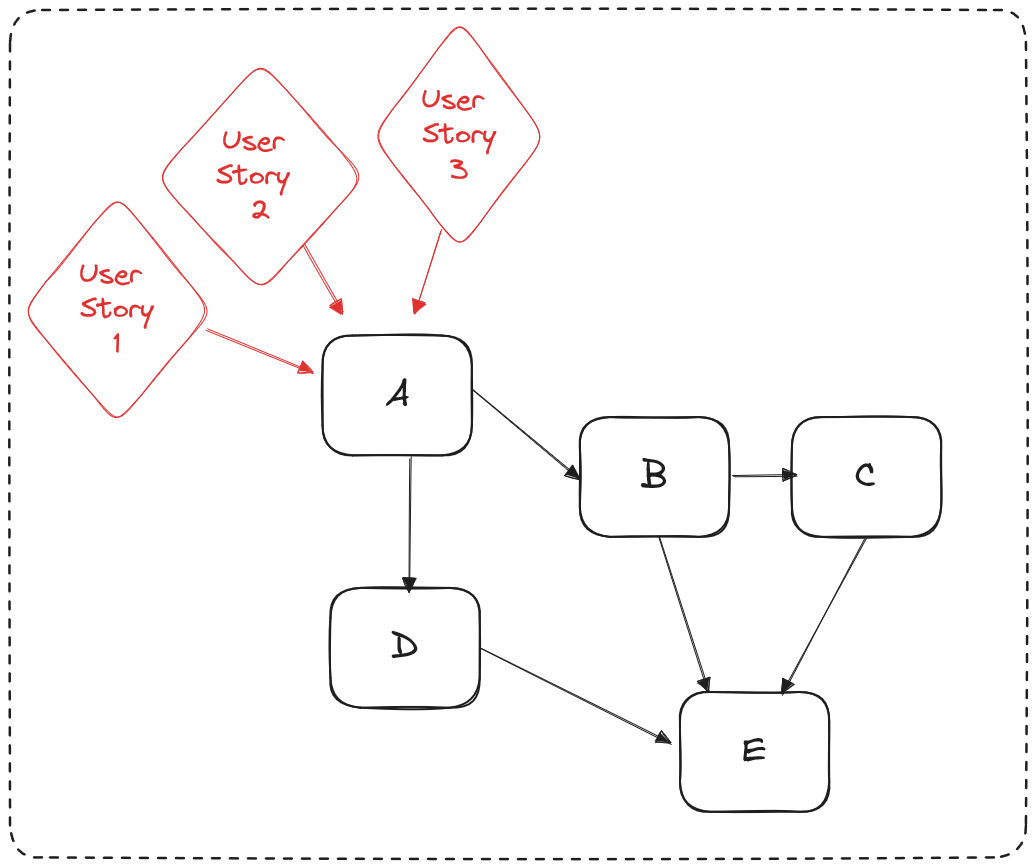
Cette stratégie a le principal avantage de rendre les tests beaucoup moins fragiles car les APIs sont en pratique beaucoup plus stables. Puisqu’elles sont couplées à des parties extérieures du module, leur changement nécessiterait beaucoup plus d’efforts. A contrario, les autres classes sont internes au module et sont en principe invisibles aux parties extérieures du module. Elles sont soumises à beaucoup plus de modifications à chaque ajout de nouvelles fonctionnalités ou à chaque tâche de refactoring. Ces modifications deviennent ainsi beaucoup moins coûteuses car moins susceptibles de faire échouer les tests.
Cependant, le périmètre testé devient plus important et une régression détectée par un test sera plus difficile à déboguer. Nous suivons ici une approche par tests solidaires. Le système testé ici n’est plus une classe, mais le comportement d’un module entier. Cela signifie qu’ajouter une nouvelle méthode dans une classe n’implique pas nécessairement l’écriture d’un nouveau test. Un test sera ajouté uniquement si un nouveau comportement du module doit être mis en œuvre.
Le nombre de doubles à utiliser est néanmoins fortement réduit. Dans cette stratégie, les doubles ne deviennent nécessaires que pour les parties qui augmentent le temps des tests ou pour les ressources partagées qui réduisent l’isolation entre les tests. Cela peut inclure les appels IO, les bases de données, les appels à des systèmes extérieurs, etc.
Cette stratégie est toutefois possible seulement dans des bases de code avec une architecture modulaire, c’est à dire qui contient des modules métiers avec un bon niveau de couplage et de cohésion. Dans une base de code avec une architecture en spaghetti, c’est à dire avec un fort niveau de couplage entre modules, il sera difficile de tester les modules séparément entre eux.
Cette façon d’implémenter des tests à pousser certains de proposer une nouvelle illustration pour représenter cette stratégie : la diamond testing.
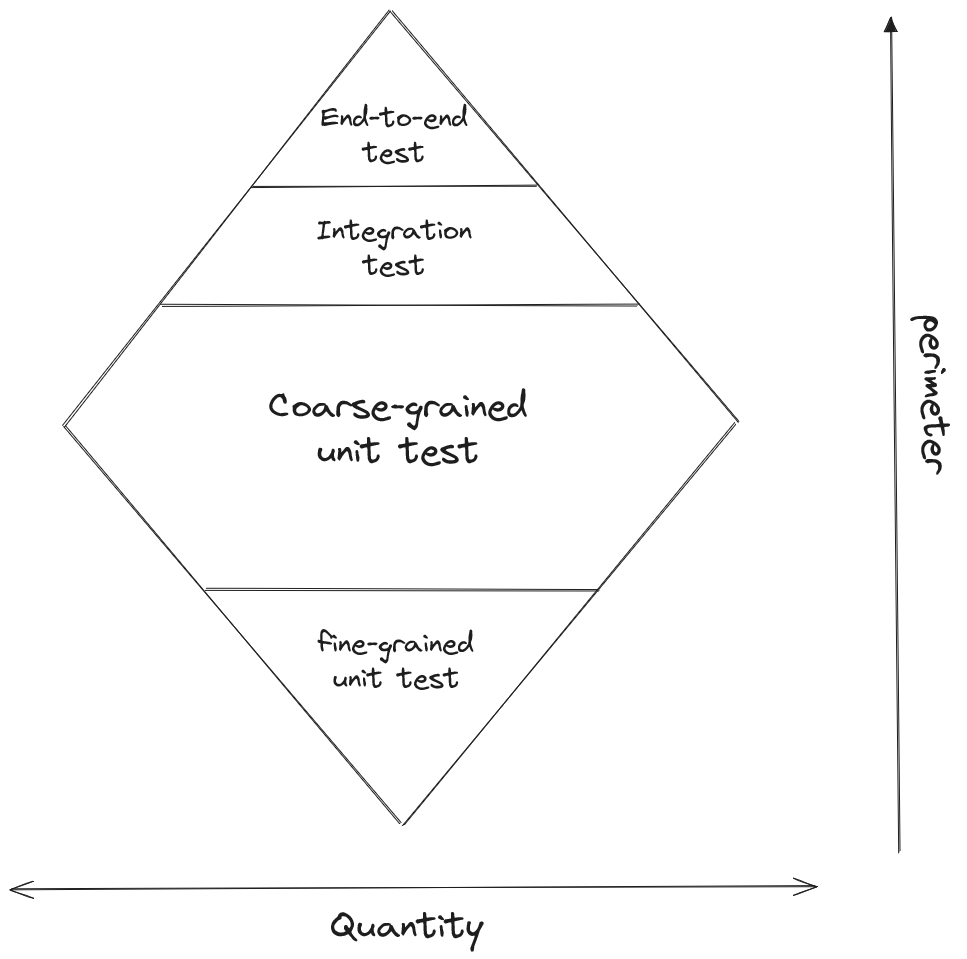
Les tests unitaires à grain fin (fine-grained unit test), c’est-à-dire des tests qui ont un périmètre plus petit (par exemple un test au niveau d’une seule classe) sont ici en plus petite quantité que dans la stratégie de la pyramide des tests. Par contre, les tests qualifiés d’unitaires à grain grossier (coarse-grained unit test), c’est-à-dire les tests qui couvrent un périmètre de plusieurs classes, sont ici beaucoup plus nombreux. Ils correspondent aux tests au niveau des APIs public des modules. Les tests de plus haut niveau qui couvrent plusieurs modules ou le système en entier sont toujours présents et en moindre quantité.
Les tests unitaires à bas niveau peuvent néanmoins être intéressants à des fins de développement pour comprendre le fonctionnement d’une classe ou pour pratiquer des techniques de TDD sur des périmètres plus petits. Ces tests peuvent cependant être supprimés une fois que l’implémentation est développée et qu’un test de plus haut niveau couvre ce périmètre.
Conclusion
Soyons honnêtes: nous parlons ici de problèmes de luxe. Nous nous retrouvons souvent dans des situations où il n’y a pas du tout de tests unitaires, dans un code legacy dont l’architecture est souvent peu modulaire et difficile à tester. Cependant, il est important de comprendre cet aspect des tests unitaires lors de la mise en place d’une stratégie de test dans un nouveau projet ou au sein d’une équipe de développement ayant des compétences avancées en test.
Ressources
- Outside-in Diamond pour écrire des tests Antifragiles & orientés métier - Thomas Pierrain ****
- TDD, Where Did It All Go Wrong (Ian Cooper) ****
- https://cucumber.io/blog/bdd/eviscerating-the-test-automation-pyramid/
- https://martinfowler.com/articles/2021-test-shapes.html
- https://martinfowler.com/articles/mocksArentStubs.html
- https://martinfowler.com/bliki/TestPyramid.html
- https://martinfowler.com/bliki/UnitTest.html
- https://martinfowler.com/articles/practical-test-pyramid.html