
Et si vous regardiez Git comme une base de donnée ? – Les entrailles
Aujourd’hui, tout le monde ou presque utilise Git comme outil de gestion des sources. Mais n’avez-vous jamais pensé à utiliser Git pour autre chose que gérer vos codes sources ?
Pour ma part c’est, entre autre, la lecture de progit et du chapitre dédié aux entrailles de Git qui a commencé à m’y faire penser. En effet, si vous regardez (vraiment) bien, git peut être vu comme une “simple” base de donnée clé/valeur. Bon ok, simple mais avec tout de même une gestion de l’historique, faut pas oublier ce qui fait l’essence de Git quand même. Et c’est là tout l’intérêt de la chose.
Lors du dernier Sogiday, nous avons eu l’occasion de travailler sur ce point : utiliser Git comme moteur de stockage pour une application.
Voici donc la première partie relatant cette exploration : les entrailles deGit !
Et si on commençait en parlant un peu de Git quand même ?
Pourquoi vouloir utiliser Git pour stocker des données (autre que du code) ? C’est pas faute d’avoir un grand nombre de bases de données disponibles.

Oui, mais. Il y a plein de choses sympa avec Git. La première étant évidemment l’accès à l’historique. Pouvoir remonter dans le temps peut être vraiment intéressant suivant les données que l’on manipule. Et avec Git c’est en standard (c’est un peu le but…).
Mais Git permet aussi de facilement gérer la réplication. Il suffit de faire un clone.
Git est aussi plutôt pratique pour scripter des actions. Si on souhaite envoyer une notification à chaque fois qu’une donnée est modifiée, il suffit d’utiliser les hooks.
Une autre raison est de pouvoir imaginer sauvegarder des données simplement dans une branche d’un dépôt de code. Par exemple que les bugs, le backlog, les choses à faire, votre kanban, etc., peuvent être persistés directement dans une branche de votre dépôt, juste à côté de votre code. Ces données deviennent donc synchrônes de votre code, vous clonez votre logiciel vous avez automatiquement les choses à faire. Sympa, non ?
Et puis ça semble fun aussi !

Enregistrer une donnée dans Git
La première étape est de pouvoir enregistrer une donnée dans Git.
La version naïve serait la suivante :
- créer un fichier dans un dépôt Git
- écrire les données qu’on souhaite dans le fichier
- committer le fichier
Ok, ça fonctionne. Par contre, ce n’est quand même pas génial. Il faut gérer les fichiers à la main. Faire des commits et autre. En gros, juste écrire un wrapper au dessus des commandes haut niveau de Git.
Le problème, c’est qu’on n’est pas tellement au niveau du stockage des données, on est au niveau du stockage des fichiers. Et c’est pas exactement pareil. Et surtout, Git nous offre des outils bien plus précis.
Git permet de créer des blobs de données, sans manipuler des fichiers. Et ça c’est cool.
Git, clés et valeurs
Allez, un petit exemple :
$ echo '{"hello":"world!"}' | git hash-object -w --stdin
5be7403d30e5ecca8454ccd65391603a3adaf128Et là, j’ai un blob. Alors oui, en vrai un fichier a été créé :
$ find .git/objects -type f
.git/objects/5b/e7403d30e5ecca8454ccd65391603a3adaf128Et on peut évidemment demander à git de nous afficher la valeur correspondant à ce hash :
$ git cat-file -p 5be7403d30e5ecca8454ccd65391603a3adaf128
{"hello":"world!"}Nous avons alors une base de donnée clé/valeur ! Pour une valeur on nous donne une clé, et si on demande à Git la valeur de la clé, il nous la donne. C’était pas si dur quand même 🙂
Enfin presque.
Le problème est que si nous changeons la valeur… la clé va changer. Et là nous sommes face à un sérieux problème. Comment accéder correctement à une valeur si la clé change tout le temps ?
Promenons-nous dans les bois, pendant que…
En effet, la solution se trouve derrière un arbre.
$ git update-index --add --cacheinfo 100644
5be7403d30e5ecca8454ccd65391603a3adaf128 1.json
$ git write-tree
3445f005406e920e5f91d2ff312c2a43794f97b0Nous venons de créer un tree qui pointe vers notre blob. Mais surtout, nous venons d’ajouter une clé, 1.json, qui elle ne devrait pas bouger à chaque modification de valeur.
Et histoire que tout soit bien enregistré, nous pouvons commiter le tree ce qui va permettre de l’horodater, d’ajouter un message lors de la création.
$ git commit-tree -m 'add 1' 3445f005406e920e5f91d2ff312c2a43794f97b0
3782de116baa41923d371e979034251d797a9d5aHistoire de vous assurer que tout s’est bien passé comme prévu, vous pouvez demander à Git de vous afficher les informations liées à ce hash :
$ git show 3782de116baa41923d371e979034251d797a9d5a
commit 3782de116baa41923d371e979034251d797a9d5a
Author: Yves Brissaud <…@…>
Date: Tue Feb 11 11:47:35 2014 +0100
add 1
diff --git a/1.json b/1.json
new file mode 100644
index 0000000..5be7403
--- /dev/null
+++ b/1.json
@@ -0,0 +1 @@
+{"hello":"world!"}Il manque enfin une dernière chose : il nous faut une référence pour pouvoir y accéder facilement.
$ git update-ref refs/heads/master 3782de116baa41923d371e979034251d797a9d5aSi on regarde le fichier .git/refs/heads/master nous avons bien le commit créé :
$ cat .git/refs/heads/master
3782de116baa41923d371e979034251d797a9d5aNous avons donc la structure suivante :
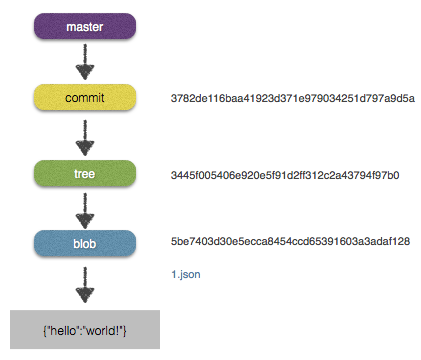
Ok c’est bien joli tout ça, mais on va pas maintenant devoir faire un checkout et lire le fichier à la main quand même ? Evidemment non, sinon ça ne servirait à rien et le côté base de données serait assez peu pratique.
$ git show master:1.json
{"hello":"world!"}Tree et blobs en chaine
Alors, plutôt simple, non ? Maintenant, pour bien comprendre comment cela fonctionne, faisons la même chose avec une clé plus complexe.
Au lieu d’enregistrer mon blob sous 1.json je vais le faire sous items/json/1.json :
$ git update-index --add --cacheinfo 100644
5be7403d30e5ecca8454ccd65391603a3adaf128 items/json/1.json
$ git write-tree
7eccf3dc9a845af20fca5f41c9d0f5077e167c12A ce moment on ne voit pas beaucoup de différences. Et pourtant ! Si vous regardez dans le répertoire .git/objects vous n’avez pas 2 objets (le blob et le tree) mais 4 :
$ find .git/objects -type f
.git/objects/34/45f005406e920e5f91d2ff312c2a43794f97b0
.git/objects/5b/e7403d30e5ecca8454ccd65391603a3adaf128
.git/objects/7b/b488cbad32ad64e1a625920685f59322e9951f
.git/objects/7e/ccf3dc9a845af20fca5f41c9d0f5077e167c12Pour commencer à explorer, regardons ce qui est derrière 7eccf3dc9a845af20fca5f41c9d0f5077e167c12 :
$ git show -p 7eccf3dc9a845af20fca5f41c9d0f5077e167c12
tree 7eccf3dc9a845af20fca5f41c9d0f5077e167c12
items/Nous avons bien un tree, comme précédemment. Mais celui-ci contient uniquement items/ comme enfant, et non items/json/1.json par exemple.
Visualisons alors l’arbre :
git ls-tree -r -t 7eccf3dc9a845af20fca5f41c9d0f5077e167c12
040000 tree 7bb488cbad32ad64e1a625920685f59322e9951f items
040000 tree 3445f005406e920e5f91d2ff312c2a43794f97b0 items/json
100644 blob 5be7403d30e5ecca8454ccd65391603a3adaf128 items/json/1.jsonVoici donc ce qui se cache derrière. Notre arbre contient un enfant items. Qui est un arbre contenant un enfant json. Qui est un arbre contenant un blob 1.json. Vous pouvez aussi faire un show sur chaque hash pour voir le détail.
Vous pouvez alors créer un commit et mettre à jour master :
$ git commit-tree -m 'add 1' 7eccf3dc9a845af20fca5f41c9d0f5077e167c12
1838b5ba48b0f811d30ced3f249687e1780c544e
$ git update-ref refs/heads/master 1838b5ba48b0f811d30ced3f249687e1780c544eLa structure est donc désormais ainsi :
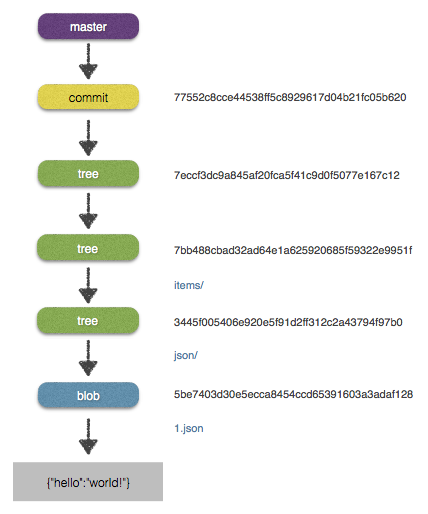
Bien évidemment vous pouvez toujours récupérer le contenu par votre clé :
$ git show master:items/json/1.json
{"hello":"world!"}Conclusion
Cette première partie à la découverte (succinte) de Git est terminée. Vous avez pu voir que git nous offre réellement la possibilité d’utiliser ses couches internes et nous expose son modèle de stockage. Ceci permet d’imaginer de nouvelles utilisations de git et surtout autrement qu’en wrappant les commandes Git de haut niveau ce qui serait ni agréable, ni fiable, ni amusant.
Le prochain article vous permettra de réaliser la même chose qu’ici mais intégré dans un code Ruby.
Un dernier point sur git avant de se quitter. Sogilis dispense aussi des formations Git !
Ressources
- Git: the NoSQL database par Brandon Keepers
- Git Internals : Chapitre 9 de Pro Git